Octavian Palade
Octavian Palade
Meta AI a creat primul model AI, NLLB-200 care traduce în 200 de limbi la cea mai înaltă calitate, validat prin evaluări complexe pentru fiecare dintre acestea.
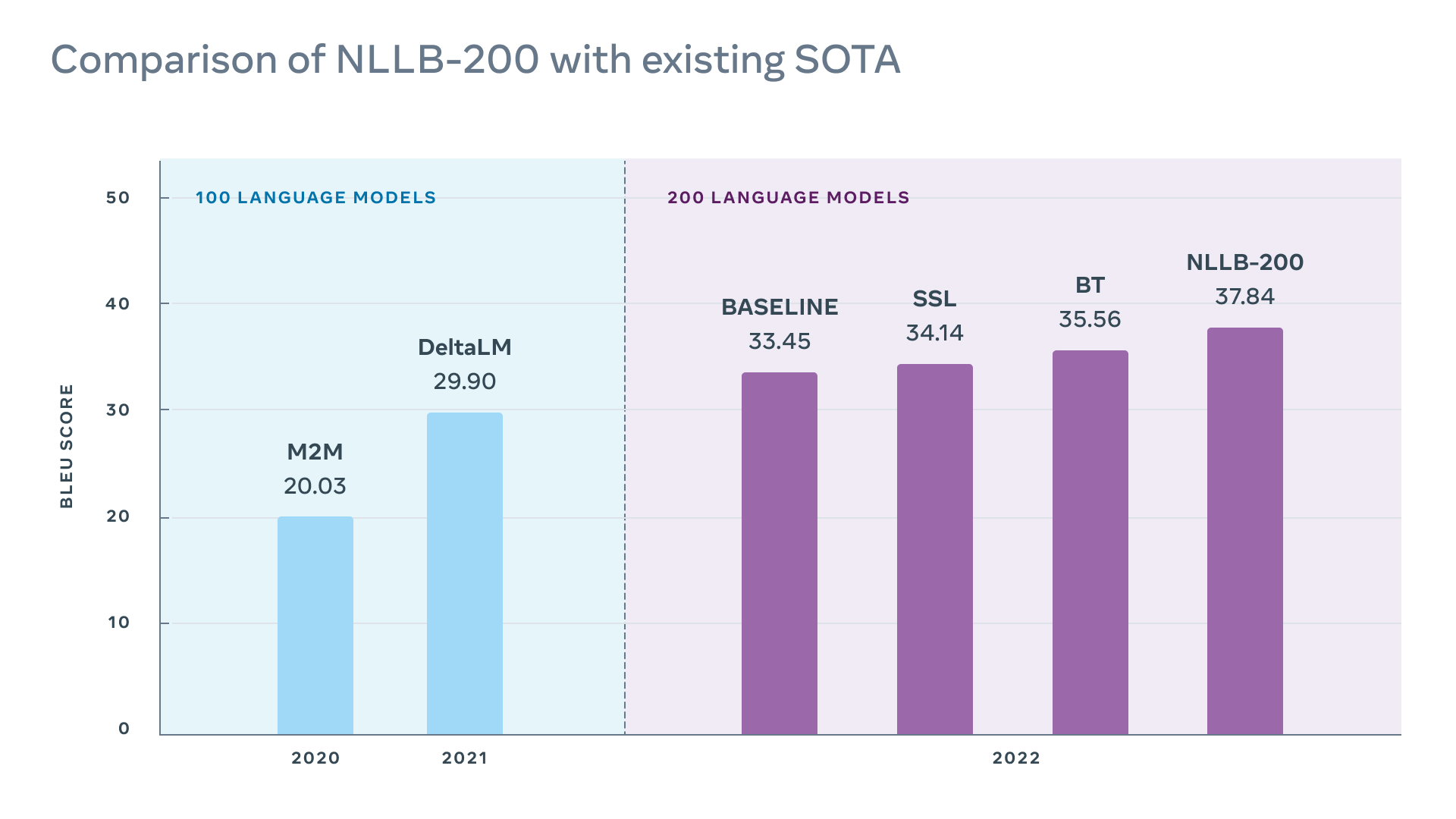
În plus, compania a creat un nou set de date pentru evaluare, FLORES-200, și a măsurat performanța modelului NLLB-200 în fiecare limbă pentru a se asigura că traducerile sunt de calitate. NLLB-200 depășește în medie cu 44% soluția din generația precedentă.
Potrivit reprezentanților companiei, Meta utilizează tehnici de modelare și informații din proiect pentru a îmbunătăți și a extinde traducerile automate pe Facebook, Instagram și chiar pe Wikipedia.
Modele NLLB-200, FLORES-200, cod pentru instruirea modelelor și cod pentru recrearea setului de date pentru instruire, vor fi puse în sistem open-source la dispoziția altor cercetători pentru ca aceștia să le poată valorifica și să își îmbunătățească instrumentele de traducere.

NLLB-200: Un pas important pentru traducerea limbilor africane
NLLB-200 traduce în 200 de limbi cu rezultate de cea mai bună calitate. Multe dintre aceste limbi, cum ar fi kamba și lao, nu erau complet sau deloc compatibile nici cu cele mai bune instrumente de traducere existente. Mai puțin de 25 de limbi africane sunt în prezent acceptate de instrumente de traducere folosite la scară largă, dintre care multe au rezultate de slabă calitate. Însă NLLB-200 acceptă 55 de limbi africane cu rezultate de calitate înaltă.
Acest model poate asigura traduceri de calitate pentru limbi vorbite de miliarde de oameni de pe tot globul. În total, scorurile BLEU ale modelului NLLB-200 sunt în medie cu 44% mai bune decât soluția din generația precedentă pentru toate cele 10 mii de direcții ale benchmarkului FLORES-101. În cazul unor limbi din Africa și India, rezultatele sunt cu peste 70% mai bune decât cele ale sistemelor de traducere recente.
NLLB-200 de la Meta - un model AI open source
Noul model este disponibil în regim open source, iar reprezentanții Meta susțin că urmează să publice mai multe instrumente de cercetare pentru a le permite altor cercetători să extindă aceste eforturi în mai multe limbi și să dezvolte tehnologii mai incluzive. În plus, Meta AI le oferă subvenții în valoare de până la 200.000 USD organizațiilor non-profit pentru utilizarea în lumea reală a modelului NLLB-200.
Traduceri mai bune pentru a opri informațiile false?
Progresele înregistrate în cercetarea NLLB vor susține peste 25 de miliarde de traduceri difuzate în fiecare zi în Noutăți Facebook, pe Instagram și pe celelalte platforme ale Meta.

”Ca să vă faceți o idee, modelul în 200 de limbi are peste 50 de miliarde de parametri și l-am antrenat folosind noul nostru Research SuperCluster, unul dintre cele mai rapide supercomputere AI din lume. Progresele înregistrate vor permite peste 25 de miliarde de traduceri în fiecare zi, în aplicațiile noastre”, a declarat Mark Zuckerberg, fondator Meta, într-o postare pe Facebook.
Potrivit companiei, traducerile extrem de precise în mai multe limbi pot, de asemenea, să contribuie la identificarea conținutului dăunător și a informațiilor greșite, la protejarea integrității procesului electoral și la reducerea cazurilor de exploatare sexuală și trafic de persoane online. Tehnicile de modelare și informațiile din cercetările Meta bazate pe NLLB sunt aplicate acum și în sistemele de traducere utilizate de editorii Wikipedia.
Traducerea este unul dintre cele mai interesante domenii în care se utilizează AI, datorită impactului său asupra vieții noastre cotidiene. NLLB înseamnă mult mai mult decât îmbunătățirea accesului utilizatorilor la conținutul de pe web. Acesta va ajuta persoanele să contribuie la și să distribuie informații în diverse limbi.
Parteneriat NLLB-200 - Wikipedia
Meta a mai anunțat și faptul că a încheiat un parteneriat cu Wikimedia Foundation, organizația non-profit care găzduiește Wikipedia și alte proiecte cu informații gratuite, pentru a contribui la îmbunătățirea sistemelor de traducere de pe Wikipedia. Există versiuni ale platformei Wikipedia în peste 300 de limbi, dar majoritatea au mult mai puține articole decât cele peste 6 milioane disponibile în engleză. Această discrepanță este mare mai ales pentru limbile vorbite în principal în afara Europei și a Americii de Nord. De exemplu, există aproximativ 3.260 de articole Wikipedia în lingala, o limbă vorbită de 45 de milioane de persoane în Republica Democrată Congo, Republica Congo, Republica Centrafricană și Sudanul de Sud. Compară această cifră cu o limbă precum suedeza, care are 10 milioane de vorbitori în Suedia și Finlanda și peste 2,5 milioane de articole.
Editorii Wikipedia folosesc acum tehnologia pe care se bazează NLLB-200, prin intermediul instrumentului de traducere a conținutului de la Wikimedia Foundation, pentru a traduce articole în peste 20 de limbi cu resurse reduse (cele care nu au seturi de date mari pentru instruirea sistemelor AI), inclusiv 10 care nu erau acceptate în trecut de niciun instrument de traducere automată de pe platformă.
”Posibilitatea de a comunica în orice limbă vorbită este o superputere pe care o oferă Inteligența Artificială, dar pe măsură ce continuăm să progresăm, munca noastră în domeniul Inteligenței Artificiale îmbunătățește tot ceea ce facem -- de la a afișa cel mai interesant conținut pe Facebook și Instagram, la a recomanda reclame cât mai relevante și până la a menține serviciile noastre drept un spațiu sigur pentru toată lumea”, a mai scris fondatorul Facebook.